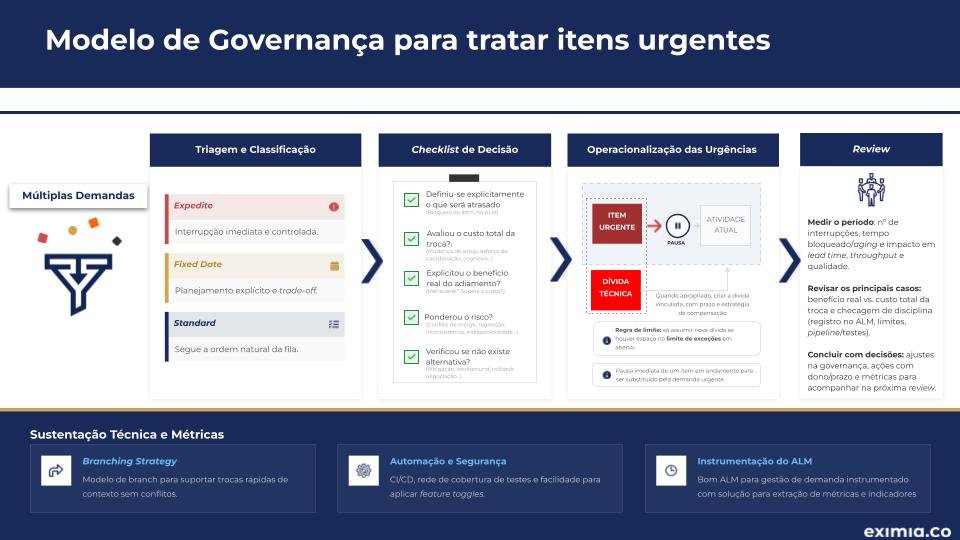
1. Agendamento Automático de Recursos (Schedules) Economia de 20-30% em ambientes de desenvolvimento
O desperdício mais visível em operações de nuvem ocorre em ambientes não produtivos. Com base na experiência prática acumulada em projetos de consultoria da eximia.co, observa-se que máquinas de desenvolvimento, testes e staging frequentemente permanecem em execução contínua, mesmo fora do horário comercial, durante fins de semana e em períodos de inatividade. Análises recorrentes realizadas em clientes ao longo de 2025 indicam que ambientes de QA operando em regime 24/7 consomem, em média, cerca de 70% mais recursos do que o necessário para sustentar essas cargas de trabalho.
Implementação em AWS: O AWS Instance Scheduler fornece uma solução serverless que executa shutdown/startup automático baseado em tags. A arquitetura utiliza EventBridge para disparar funções Lambda em intervalos definidos, que validam instâncias EC2 e RDS contra configurações armazenadas em DynamoDB. Em alguns casos, organizações implementando esse controle em ambientes de desenvolvimento relataram redução de custos em torno de 70% em períodos não-operacionais.
Extensão Multicloud:
- Azure: Azure Automation com runbooks PowerShell integram-se a Azure Logic Apps para orquestração visual sem necessidade de código.
- GCP: Cloud Scheduler dispara Cloud Functions que interrompem instâncias computacionais e bases de dados através da API Compute Engine.
Governança com Tags: Implementar tags padronizadas como schedule-policy: business-hours-only ou environment: development é crítico. Reforçar o controle via Infrastructure-as-Code (Terraform, CloudFormation) garante que nenhuma instância escape da política. Configurar janelas de graceful shutdown (30 segundos) permite que aplicações limpem conexões e salvem estado temporário.
Economia Esperada: 20-30% em ambientes não-produtivos em 30 dias, sem risco técnico quando implementado corretamente.
2. Rightsizing de Instâncias
Economia de 25-35% no custo de capacidade computacional
Overprovisioning, ou superdimensionamento, é estrutural em operações de nuvem. Equipes criam instâncias “para o futuro” ou com margem de segurança excessiva, resultando em máquinas rodando com CPU<10%, memória<30% e utilização de network bandwidth<5%. Esses recursos drenam orçamento sem entregar valor proporcional.
Análise Correta de Rightsizing: A recomendação deve considerar métricas agregadas em Auto Scaling Groups, especialmente para workloads efémeros (de curta duração). Análises superficiais que usam apenas CPU máximo podem ocultar o fato de que instâncias menores atendem o requisito real. nOps e ferramentas similares analisam a máxima utilização de CPU, memória, network e disco através todas as instâncias em um ASG antes de recomendar downsizing.
Ferramentas AWS:
- AWS Compute Optimizer: Integra com CloudWatch para analisar p95/p99 (percentis de pico) de CPU, memória e network ao longo de 14, 32 ou 93 dias. Retorna recomendações por família de instância (exemplo: t3.large → t3.medium), com estimativa de economia mensal.
- AWS Cost Optimization Hub: Agrega mais de 15 tipos de recomendação em um dashboard único, priorizando oportunidades por impacto de custo absoluto.
Ferramentas Multicloud:
- GCP Recommender Engine: Identifica máquinas virtuais (VMs) subdimensionadas, discos órfãos e IPs desassociados com precisão superior a ferramentas genéricas.
- Azure Advisor: Recomenda downsizing de VMs e limpa recursos não utilizados automaticamente.
- Ferramentas de Terceiros: CloudZero, nOps e Flexera One oferecem rightsizing unificado para AWS, Azure e GCP, usando machine learning para detectar padrões de uso que ferramentas nativas podem perder.
Processo Seguro:
- Clonar configuração de instância original para nova instância menor.
- Monitorar ambas por 7-14 dias para validar a performance.
- Comparar latência, throughput e taxas de erro antes de desativar o recurso original.
- Empregar testes de carga com ferramentas como JMeter, Locust e K6 para confirmar capacidade sob pico e situações de stress.
Economia Esperada: 25-35% em custos computacionais em 30 dias. Uma empresa típica com 200 instâncias EC2 vê economia média de $12-18k/mês.
3. Commitments – Saving Plans e Instâncias Reservadas
Economia de 25-40% na contratação de recursos computacionais
Workloads estáveis, como bancos de dados core, APIs de produção e serviços base, executam 24/7/365 com padrão de consumo previsível. Pagar on-demand para esses recursos é ineficiente financeiramente. Planos de comprometimento reduzem custo drasticamente através de reservas de capacidade.
Opções AWS:
- Reserved Instances (RIs): Compromisso com instância específica (tamanho, família, região) por 1 ou 3 anos. Oferece até 72% de desconto sobre contratação on-demand.
- Savings Plans (Compute): Compromisso monetário/hora sobre qualquer instância (família, tamanho, sistema operacional, região flexível). Oferece até 65% de desconto.
- Estratégia Híbrida: Usar RIs para workloads core (70% do baseline previsível) + Savings Plans para capacidade dinâmica. Azure e GCP aplicam desconto RI primeiro, depois Savings Plans em cima do uso excedente, otimizando automaticamente.
Opções Multicloud:
- Azure: Savings Plans (até 65%) + Reserved Instances (até 72%), aplicados automaticamente na melhor ordem.
- GCP: Committed Use Discounts (CUDs) oferecem até 70% de desconto para 1 ou 3 anos em Compute Engine.
Detalhe Crítico—Hybrid Benefit:
Hybrid Benefit (ou Azure Hybrid Benefit) é um benefício de licenciamento que permite reutilizar licenças on-premises (principalmente Windows Server e SQL Server) na nuvem, reduzindo bastante o custo.
- Windows Server com Azure Hybrid Benefit reduz a mensuração em ~50%, permitindo RIs/Savings Plans ainda mais eficientes.
- Licenças SQL Server On-Premises podem ser migradas para Azure, amplificando a economia.
Economia Esperada: 25-40% em capacidade computacional não-spot através de comprometimento. É o método mais seguro para início de FinOps sem mudança de arquitetura.
4. Spot Instances para Workloads Tolerantes
Possibilidades de economia de até 90% para cargas de trabalho interruptíveis
Spot instances oferecem capacidade de nuvem ociosa por uma fração do preço on-demand. A contrapartida é o risco de interrupção com aviso curto. Para workloads batch, CI/CD builders e processamento de dados, spot instances representam otimização essencial.As
| Aspecto | AWS Spot | GCP Preemptible | Azure Spot |
| Economia | 60-90% | 60-91% | 60-90% |
| Aviso Interrupção | 2 minutos | 30 segundos | 30 segundos |
| Runtime Máximo | Ilimitado | Ilimitado (Spot VMs) | Ilimitado |
| Taxa Interrupção (típica) | 0,8-2,3% | Similar | Similar |
| Orquestração | ASG, Spot Fleet | Managed Instance Groups | VM Scale Sets |
Estratégia Segura:
- Diversificação de Instâncias: Configurar 10-15 tipos diferentes de instância em Auto Scaling Groups aumenta a disponibilidade pois taxas de interrupção variam por tipo de instância.
- Checkpoint e Replicação: Para workloads batch (ML training, data processing), salvar estado a cada 10-30 minutos em S3/GCS/Blob Storage. Um restart automático retomará a partir do último checkpoint.
- Tolerância de latência: APIs críticas de cliente não devem rodar em spot. Use spot para: analytics batch, CI/CD builders, ML training, background jobs.
Exemplo de Economia: Uma organização com 50 instâncias m5.2xlarge ($0.384/h on-demand) em Kubernetes pode rodar a mesma carga, em situação ideal, em 60 instâncias spot (m5.2xlarge a ~$0.077/h), reduzindo custo em 80% com buffer de capacidade melhor.
Economia Esperada: 60-90% em workloads batch/não críticos. Redução média 40-50% em ambiente misto (on-demand + Spot + Reserved).
5. Storage Cleanup – Limpeza de Storage
Economia de 5-8% em armazenamento
Snapshots, discos órfãos (EBS volumes não anexados), backups versionados e dados frios permanecem armazenados indefinidamente em storage premium, acumulando centenas ou milhares de dólares mensais. Políticas de lifecycle aplicam automação para transição entre tiers de armazenamento.
Implementação AWS (S3 Lifecycle Policies):
- Dados > 30 dias → Standard-IA (reduz 60% vs. Standard)
- Dados > 90 dias → Glacier Instant (reduz ~80%)
- Dados > 365 dias → Glacier Deep Archive (reduz 95% vs. Standard, com retrieval fee)
- Deletar versões antigas automaticamente e manter apenas últimas 3 versões
Aplicação: Bucket com 500GB Standard + 1TB histórico migrando para Standard-IA/Glacier reduz custo de storage anualmente em $4-6k.
Implementação Multicloud:
- Azure Blob Storage: Lifecycle management transiciona os blobs entre Hot→Cool→Archive automaticamente. Sem custo para policies; paga-se por operações de API.
- GCP Cloud Storage: Ciclos de vida transitam de Standard→Nearline→Coldline→Archive. Cuidado: Taxas de recuperação em tiers frios podem invalidar economia se o acesso for frequente.
Governança Crítica:
- Analisar padrões de acesso reais via S3 Access Logs / GCP Monitoring antes de transicionar para archive.
- Retenção mínima: Glacier (30 dias mínimo), Glacier Deep Archive (180 dias mínimo). Deletar antes do prazo mínimo de retenção incorre em taxa de exclusão antecipada.
- Versionamento sem lifecycle é uma armadilha: versões antigas acumulam e quadruplicam storage sem razão.
Economia Esperada: 5-8% em custos totais de nuvem para organizações com mais de 5 TB de dados. Maior impacto em casos de armazenamento de logs, backups e datasets históricos.
6. Tagging Obrigatório para Alocação e Automação
Incrementa a visibilidade dos custos de nuvem em índices superiores a 45%
Sem tags, não há rastreabilidade de quem consome o quê. Sem visibilidade, não há controle. FinOps maduro exige tagging estruturado: owner, project, environment, cost-center, etc. Tags são a fundação para todos os outros controles.
Exemplo de Estrutura de Tagging Multicloud Unificada:
| Tag | Valores Exemplo | Escopo | Propósito |
| owner | team-platform, eng-database | Obrigatório | Responsabilidade e accountability |
| environment | production, staging, development | Obrigatório | Tier de aplicação |
| project | crm-migration, data-pipeline-v2 | Obrigatório | Rastreamento de projeto |
| cost-center | cc-engineering, cc-data | Obrigatório | Alocação financeira |
| backup-policy | daily-7d, monthly-1y | Opcional | Governança de retenção |
| schedule-policy | business-hours, 24-7 | Opcional | Automation de schedules |
Enforcement Automático:
- AWS: CloudFormation templates com tags default; AWS Config rule para auditoria de recursos sem tags.
- Azure: Azure Policy para impedir o provisionamento sem tags; Azure Blueprints para aplicar tags em escala.
- GCP: Variáveis no Terraform reforçam tags; GCP enforcer labels via Kubernetes RBAC para GKE.
Impacto na Alocação de Custos:
Uma organização típica com tags implementadas consegue:
- Atribuir 95%+ de custos a centros de custos(vs. 40-50% sem tags).
- Implementar showback/chargeback automático.
- Criar regras de governança: “tags sem owner bloqueiam provisionamento”.
Economia Esperada: Tagging não é economia direta. É enabler para outros 6 controles. Com tags, otimizações automáticas (schedules, rightsizing, alertas de anomalias) são 3-5x mais eficazes. Economia indireta: 8-15% por habilitação de automação.
7. Anomaly Alerts – Alertas de Anomalia
Detecção de picos de gastos antes que virem uma surpresa
Spikes de custo ocorrem por: deployments com bug (infra infinita provisionada), workloads abandonados (ex. ambiente de teste deixado rodando), misconfigurations (queries sem limite). Detecção em tempo real evita overspend de mais de 20% em um mês.
Técnicas de Detecção:
- Baseline Histórico + Sazonalidade: Analisar 30-90 dias de história para estabelecer consumo normal. Empregar algoritmos de ML (ARIMA, Prophet, XGBoost) que aprendem padrões sazonais.
- Machine Learning Avançado: Clustering detecta que “tráfego não faz sentido para essa aplicação”.
- Threshold-Based: Simples: “se custo hoje > custo mediano últimos 7 dias + 20%, alerta”.
Ferramentas Recomendadas:
| Ferramenta | AWS | Azure | GCP | Multicloud |
| CloudZero | ✅ | ❌ | ❌ | Sim (core) |
| nOps | ✅ | ❌ | ❌ | Sim |
| Flexera One | ✅ | ✅ | ✅ | Sim |
| AWS Cost Anomaly | ✅ (nativo) | ❌ | ❌ | Não |
| Datadog | ✅ | ✅ | ✅ | Sim |
Integração de Resposta:
- Alerta → Slack/PagerDuty automaticamente.
- Link direto para a dashboard do projeto responsável.
- Ação de remediação: pausa de deployments, escalonamento para DevOps.
Economia Esperada: Sem detecção, uma anomalia típica (Ex. um ambiente de teste esquecido) custa ~20% acima da baseline em 1 mês = $2-5k de perda. Com alertas e detecção em <1 hora, se reduz o dano econômico sensivelmente.
Economia: $15-25k/ano para organização típica.
Controles FinOps: Comparação do potencial de Saving por tipo de controle.
Conclusão
Os sete controles apresentados:scheduling, rightsizing, commitments, spot instances, storage cleanup, tagging, anomaly alerts.ão práticas consolidadas pela comunidade FinOps Foundation. Implementados em sequência (Crawl → Walk → Run) e adaptados para multicloud (AWS + Azure + GCP), produzem economia comprovada de 35-40% em 90 dias, sem sacrifício de performance ou inovação.
O sucesso depende de uma governança forte (tagging reforçada), automação inteligente (não bruta), e cultura colaborativa entre engenharia e finanças. Ferramentas como AWS Cost Optimization Hub, Compute Optimizer e soluções third-party como Flexera One ou CloudZero aceleram a implementação.
Para organizações iniciando com FinOps: comece com tagging + alertas (Fase 1), expanda para scheduling + rightsizing (Fase 2), finalize com commitments + spot (Fase 3).
Para organizações maduras: paralelizar fase 2 + 3 com governança estruturada.A trajetória de FinOps não termina em 35-40% economia. É uma jornada contínua rumo à alta performance técnico/econômica, onde cada dólar gasto em nuvem se conecta diretamente ao valor de negócio entregue.