Quando repriorização vira o modo padrão de operação
Quando mudar prioridade vira rotina, a organização para de enxergar o custo da decisão e o sistema degrada silenciosamente.
Em times de desenvolvimento de software, a situação é recorrente: prioridades mudam constantemente, não raramente, mais de uma vez no mesmo dia. O trabalho inicia, é interrompido, reinicia e volta a ser interrompido. Em meio à urgência, surge o “urgente do urgente”. Antes de compreender plenamente o problema em resolução, o foco muda novamente.
No curto prazo, esse comportamento pode parecer uma resposta adaptativa a mudanças do mercado. No médio prazo, tende a se normalizar: as mudanças deixam de ser percebidas como repriorização e passam a ser tratadas como “ajustes naturais do dia a dia”. Nesse ponto, o time opera sob instabilidade estrutural: não existe um estado de fluxo sustentado, apenas transições sucessivas.
O resultado é previsível e cumulativo: perda de foco, retrabalho, improdutividade, frustração e elevação de estresse.
Urgência contínua raramente aumenta velocidade, geralmente aumenta variabilidade e imprevisibilidade
A maior causa de lead time alto não é “falta de esforço”, é a variabilidade de fluxo gerada por interrupções.
Organizações frequentemente associam urgência a velocidade. Na prática, a urgência contínua produz o efeito oposto: ela aumenta o custo de coordenação, amplia o trabalho incompleto e eleva a variabilidade do sistema. A consequência é a expansão do lead time médio e a redução da confiabilidade de entrega.
De forma recorrente, times confundem “capacidade de reagir” com “capacidade de interromper”. A primeira depende de clareza de critérios, fluxo bem gerido e qualidade técnica. A segunda apenas transfere custos para o sistema, geralmente para ser pago mais adiante, com juros.
Impactos: o custo oculto da repriorização frequente
Repriorização não é só trocar tarefas: ela cria perdas em múltiplas camadas que se acumulam ao longo do tempo e muitas vezes são invisíveis.
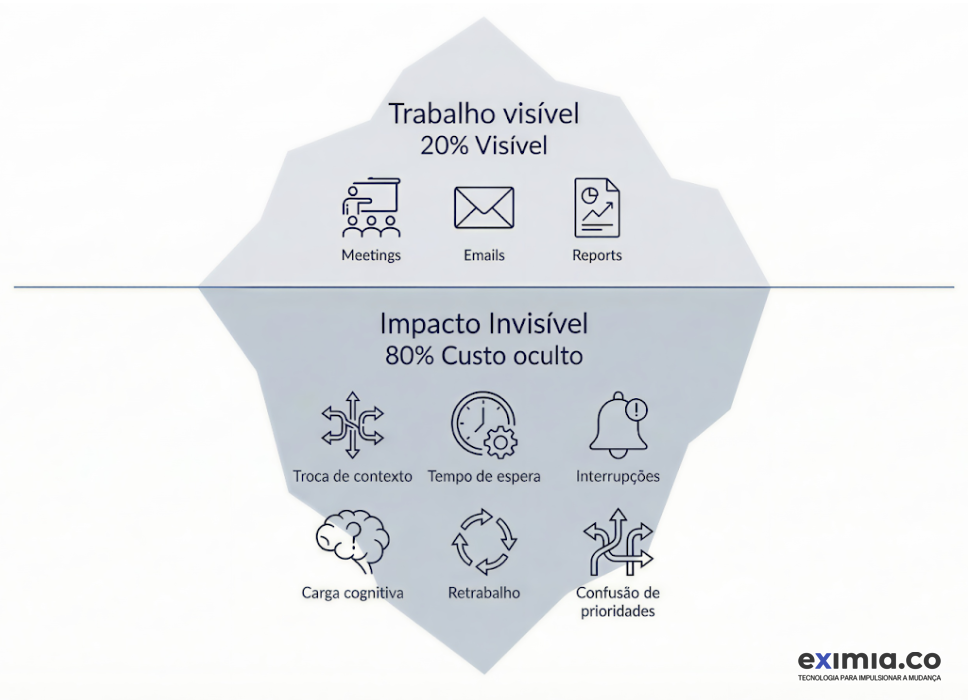
Custo cognitivo (troca de contexto)
Interromper trabalho em andamento não equivale a trocar de tarefa. Existe um custo real para “desmontar” e “reconstruir” o contexto mental do problema: entendimento do domínio, hipóteses, decisões locais, rastros de debugging e dependências técnicas. Esse custo se manifesta como tempo não produtivo, aumento de erro e maior necessidade de retrabalho.
Custo técnico (branching, integração e risco)
Mudanças de prioridade afetam diretamente a estratégia de integração e aumentam a fricção técnica do time. Entre os efeitos mais comuns:
-
Branches mais longas e mais numerosas
Quando uma demanda é interrompida, o código fica “vivendo fora” da linha principal por mais tempo. Enquanto isso, outras mudanças continuam entrando. O resultado é previsível: mais divergência, mais conflitos de merge, mais necessidade de rebase e maior chance de reintegrar código desatualizado, elevando retrabalho e risco de regressão;
-
Trabalho parcialmente integrado (feature incompleta, dependências em aberto)
Repriorização frequente incentiva integração por pedaços: partes entram, outras ficam pendentes, e o sistema passa a carregar comportamento incompleto. Isso aumenta a superfície de validação (testar combinações e estados intermediários), dificulta detectar inconsistências e pode gerar “dívida de integração”. Aquele trabalho extra apenas para fazer o todo voltar a fazer sentido;
-
Hotfixes e mudanças paralelas
Em um time que alterna frentes, é comum haver correções urgentes sendo aplicadas em paralelo ao desenvolvimento corrente. Isso cria múltiplas linhas de alteração concorrendo pelos mesmos componentes, aumenta a chance de efeitos colaterais e dificulta rastrear exatamente “o que mudou, por que e em qual contexto”. O custo aparece depois: reconciliação, harmonização e novas correções;
-
Validação comprometida pela pressa
Sob urgência, padrões de qualidade tendem a ser flexibilizados: testes ficam incompletos, revisões são apressadas e pipelines são contornados para “ganhar tempo”. O ganho é local e imediato; o custo é sistêmico: cresce a probabilidade de falha em produção, aumenta o volume de retrabalho e piora a estabilidade do sistema.
Além disso, repriorizar frequentemente impõe “tempo de setup” no ambiente: alternar branches, sincronizar dependências, recompilar, subir serviços e restabelecer cenários de teste. Quanto mais o time alterna frentes, mais a integração vira uma operação de risco e menos capacidade sobra para entregar.
Custo sistêmico (WIP, aging e previsibilidade)
A consequência menos discutida é o aumento de trabalho incompleto: itens “quase prontos”, parcialmente implementados, aguardando retorno. Isso cria um estoque oculto. Esse estoque consome capacidade (manutenção de contexto, ajustes, revalidações), mas não entrega valor. Quando o aging time cresce, o investimento já realizado deixa de se traduzir em retorno.
Na prática, esse mecanismo também reduz a confiança: o time não consegue assumir compromissos e estimar bem, porque não controla a estabilidade do próprio plano de execução.
Perguntas que devem anteceder qualquer repriorização
Se não há trade-off explícito (“o que atrasa, quanto custa, qual risco”), a decisão é impulso, não governança.
Mudanças de prioridade são inevitáveis. O que varia é o nível de governança aplicado.
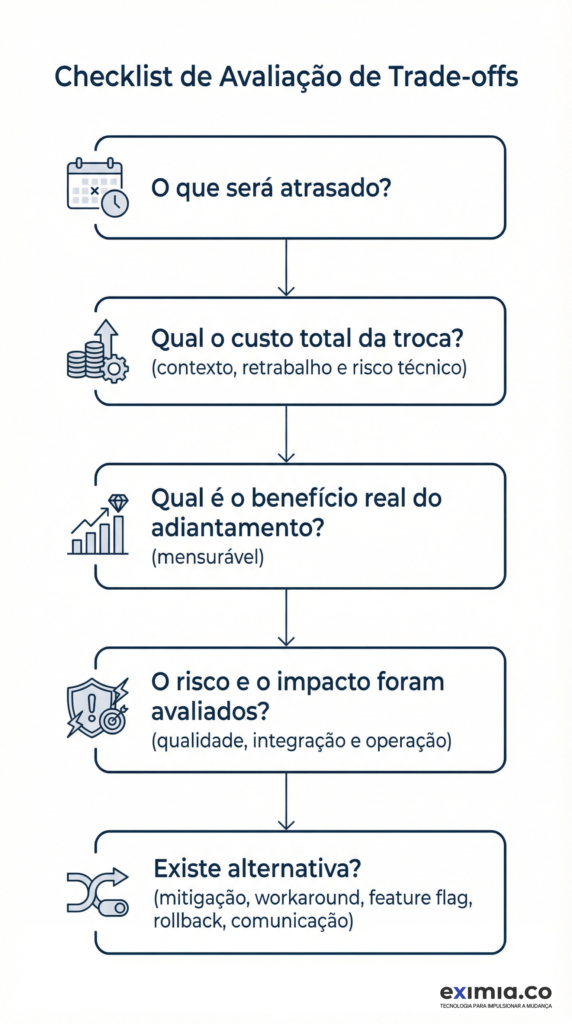
Antes de introduzir um novo “urgente”, decisões maduras precisam responder, explicitamente:
- O que será atrasado?
- Qual o custo total da troca (contexto, retrabalho e risco técnico)?
- Qual é o benefício real do adiantamento?
- O risco e o impacto foram avaliados?
- Existe alternativa?
Se essas perguntas não existem, a repriorização tende a ser tomada por pressão, não por trade-off.
É importante destacar que esse conjunto de perguntas não deve introduzir um processo lento. Ele deve introduzir responsabilidade decisória. Uma solicitação de urgência só é madura quando o solicitante consegue explicitar: (1) o que será deslocado, (2) qual risco técnico e operacional será assumido e (3) qual benefício mensurável justifica a interrupção. Sem isso, a “urgência” não é uma decisão, é um reflexo organizacional. E, nesse cenário, a engenharia passa a pagar a conta de escolhas mal formuladas.
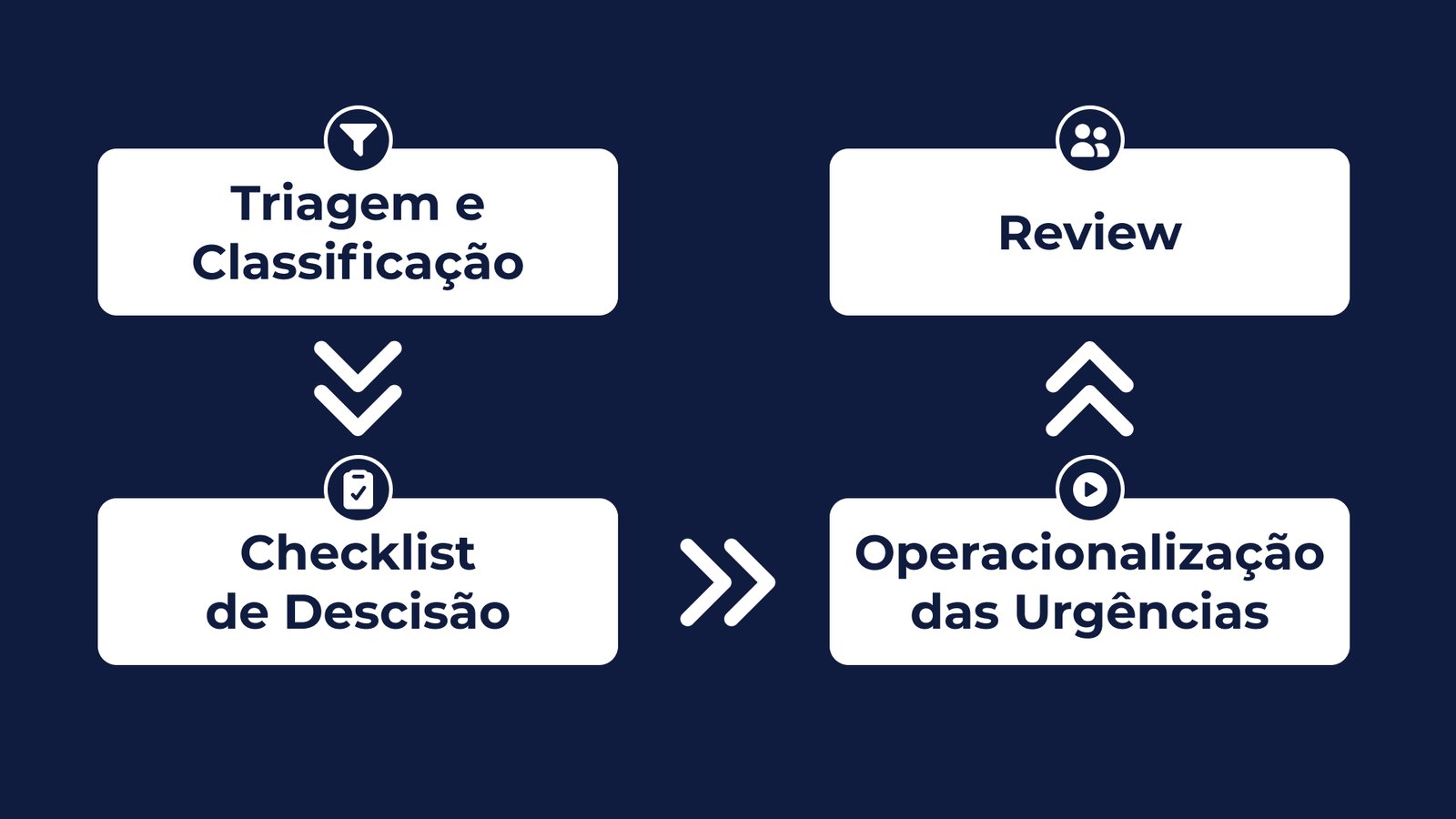
Modelo de governança recomendado para urgências e repriorizações
O objetivo não é “eliminar urgências”, mas absorvê-las com previsibilidade e custo controlado. A seguir, um modelo enxuto de gestão de repriorização.
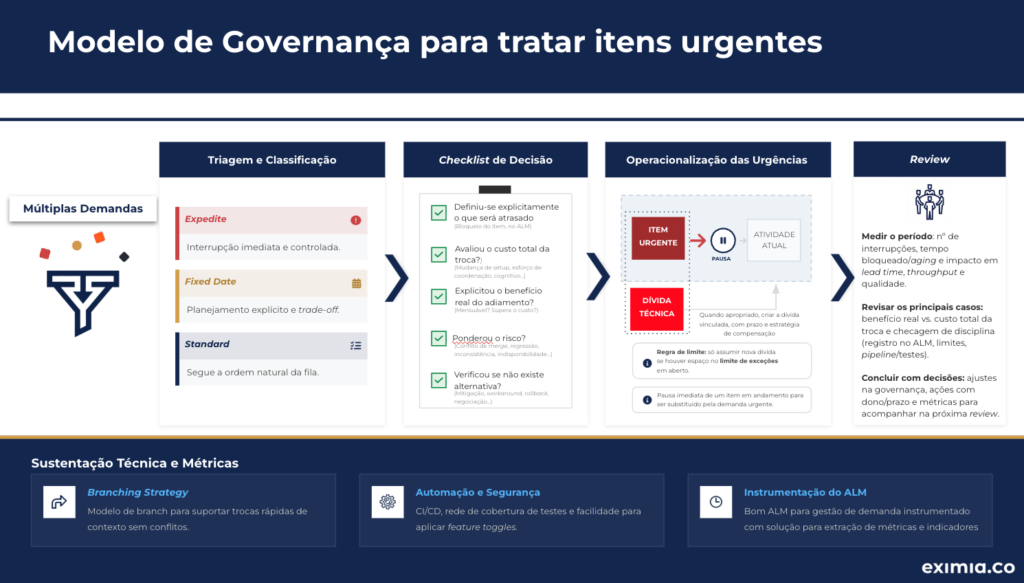
Estabeleça critérios de urgência (taxonomia operacional)
Definir critérios de urgência não significa criar uma segunda lista de prioridades. A prioridade deve continuar sendo única e visível: a ordem dos itens no board do seu ALM, da direita para a esquerda e de cima para baixo. Isso é o que protege previsibilidade: uma fila clara.
Os critérios de urgência devem ser tratados como políticas de atendimento, isto é, regras de como uma demanda entra e como ela é executada e não como um rótulo que tenta “furar fila” por definição. Em vez disso, adote Classes de Serviço, por exemplo:
- Expedite (interrupção controlada): usado apenas para incidentes reais (ex.: indisponibilidade, segurança), com rito específico e limite rígido para não virar padrão;
- Fixed Date (prazo externo): demanda com janela objetiva (regulatória, contratual), tratada com planejamento explícito e trade-off formal;
- Standard (fluxo normal): tudo que deve seguir a fila padrão do board, sem exceções;
- Intangible (dívidas técnicas): itens importantes, porém com flexibilidade, protegidos por capacidade reservada ou política de WIP (Work in Progress).
A lógica é simples: prioridade define “o que vem antes”; a classe de serviço define “como executar” e “quais limites e garantias” se aplicam.
Garanta compatibilidade com a política de branching e integração
A organização deve validar se a política de branching suporta o comportamento esperado. Se há expectativa de fast lane (classe Expedite), a engenharia precisa ser capaz de manter o sistema continuamente integrável e entregável sob volatilidade. Caso contrário, a urgência apenas desloca o custo para a integração em forma de conflito, retrabalho e regressões.
Estratégias de branching e aderência à volatilidade
- GitFlow (múltiplas branches e estabilização em etapas) tende a funcionar melhor em cadências de release mais previsíveis. Em ambientes com repriorização frequente, costuma amplificar fricção: branches vivem mais tempo, divergência cresce e hotfixes paralelos aumentam a complexidade de reconciliação.
- GitHub Flow (branch curta + PR + merge frequente na main) é mais compatível com fast lane porque reduz tempo fora da linha principal e favorece lotes menores. Porém, depende de disciplina e maturidade nos processos de engenharia: a main precisa permanecer “deployable”.
- Trunk-Based Development (integração contínua com mudanças pequenas) é o modelo mais aderente a ambientes voláteis, desde que a organização tenha maturidade em automação e qualidade. Sem isso, ele vira um acelerador de instabilidade.
Pré-requisitos técnicos para uma fast lane segura
Para que urgência não vire atalho informal, três práticas precisam estar presentes:
- Integração frequente e lotes pequenos, reduzindo divergência e custo de reintegração;
- Feature toggles e releases controlados, separando “integrar” de “expor” e reduzindo blast radius;
- Automação forte de CI/CD (Continuous Integration e Continuous Delivery), com gates mínimos inegociáveis (build, checks, testes) e feedback rápido.
Por fim, modelos mais ágeis exigem base de confiança: testes de unidade consistentes (rápidos, executados a cada mudança) e pipelines confiáveis. Sem isso, a organização fica presa a um trade-off ruim: ou reduz controle para ganhar velocidade, ou aumenta controle manual para reduzir risco e perde o benefício da fast lane.
Em outras palavras: a governança da urgência precisa ser coerente com a engenharia de integração.
Sinais de incompatibilidade (quando a política técnica está lutando contra o processo):
- Branches “eternas” e merge recorrente com alto conflito;
- Aumento de hotfixes e retrabalho pós-release;
- Pressão para “pular pipeline” ou reduzir testes para cumprir urgências;
- PRs grandes porque o time evita integrar cedo (por medo de instabilidade);
- Medo de deploy, quando o sistema só entrega quando “dá”, não quando “precisa”.
Avalie o trade-off formalmente (benefício vs. custo total)
Para cada mudança, avalie:
- Impacto da não execução imediata;
- Custo da interrupção;
- Risco técnico de integração;
- Impacto em prazos, WIP e qualidade.
Esse passo não precisa ser burocrático. Precisa ser explícito.
Instrumente a repriorização no ALM para gerar métricas (não narrativas)
Sem instrumentação, urgência vira folclore. A recomendação prática:
- Itens interrompidos devem ser marcados como bloqueados na ferramenta de ALM (Jira, Azure DevOps, etc.);
- O bloqueio deve ter motivo categorizado (ex.: “Repriorização P0”, “Hotfix”, “Mudança executiva”, etc.);
- Utilize scripts para extrair métricas ou adote soluções especializadas, como o Follow the Code da EximiaCo para extração de métricas e indicadores.
Isso viabiliza mensurar:
- Tempo perdido por interrupção;
- Impacto no lead time;
- % de tempo produtivo vs. % de tempo perdido;
- Correlação entre repriorização e produtividade/qualidade.
Monitore aging time e imponha políticas de “não esquecimento”
O aging time deve ser monitorado para evitar o acúmulo de itens “quase prontos”. Recomendações típicas incluem:
- Revisões semanais de itens com aging acima de um limiar;
- Política de “finalizar antes de iniciar novo” para itens que já consumiram capacidade relevante;
- Critérios para cancelar formalmente itens quando o valor tiver sido invalidado.
O objetivo é reduzir o estoque de trabalho interrompido que não se converte em retorno.
Implicações para liderança: o que muda quando a urgência vira processo
Quando a repriorização se torna gerenciada, a organização ganha:
- Maior previsibilidade e confiabilidade de entrega;
- Redução de retrabalho e risco técnico;
- Melhor colaboração com Negócio (trade-offs explícitos);
- Capacidade de aprender com dados (não com impressões).
Sem isso, a urgência tende a “capturar” o sistema: o time passa a operar como brigada de incêndio e, paradoxalmente, entrega menos com mais estresse e maior probabilidade de falhas.
Conclusão
A urgência não é, por si, um problema. O problema é a ausência de método para decidir, executar e medir repriorizações. Em ambientes de alta volatilidade, times de engenharia performam quando possuem critérios claros, processos compatíveis com sua estratégia técnica e instrumentação que transforma decisões em aprendizado.
A questão decisiva para liderança é simples: no seu time, urgência é uma exceção governada ou o seu modelo operacional?