Quando um sistema precisa se integrar a outros serviços, a comunicação síncrona via HTTP (Hypertext Transfer Protocol) costuma ser a primeira possibilidade. Ela é simples de entender, fácil de implementar e combina bem com fluxos em que uma requisição depende de uma resposta imediata.
O problema aparece quando esse modelo começa a sustentar fluxos críticos demais. Basta um serviço ficar lento para o restante da cadeia desacelerar junto. Basta uma dependência oscilar para a falha se espalhar em cascata. Em cenários com picos de carga, integrações externas ou etapas sensíveis, o que parecia uma escolha simples pode virar gargalo operacional.
É nesse ponto que a pergunta muda. Em vez de discutir preferência de arquitetura, vale discutir o comportamento do sistema: quando faz sentido manter o fluxo síncrono e quando a mensageria passa a ser a escolha mais segura.
Este artigo mostra, de forma técnica e pragmática, quando o HTTP síncrono continua sendo a melhor opção, quando ele passa a limitar o sistema e por que arquiteturas orientadas a mensagens existem como resposta a esses limites.
O problema da comunicação síncrona
Uma chamada HTTP entre serviços não é apenas uma troca de dados. Ela cria uma dependência direta de tempo e disponibilidade entre quem chama e quem responde. Quando um serviço A chama um serviço B de forma síncrona, três tipos de acoplamento entram em cena ao mesmo tempo:
- Acoplamento temporal: B precisa estar disponível exatamente no momento da chamada.
- Acoplamento de latência: o tempo de resposta de B afeta diretamente o SLA (Service Level Agreement) de A.
- Acoplamento de falha: se B falha, A tende a falhar junto ou a degradar seu próprio comportamento.
Em sistemas pequenos, isso costuma ser aceitável. Em sistemas distribuídos, com várias dependências e maior volume de tráfego, isso deixa de ser um detalhe de implementação e passa a ser um risco de arquitetura.
Considere um fluxo comum de compra em um e-commerce, por exemplo:
API de Pedido
→ Serviço de Pagamento (HTTP)
→ Serviço de Antifraude (HTTP)
→ Serviço de score externo (HTTP)
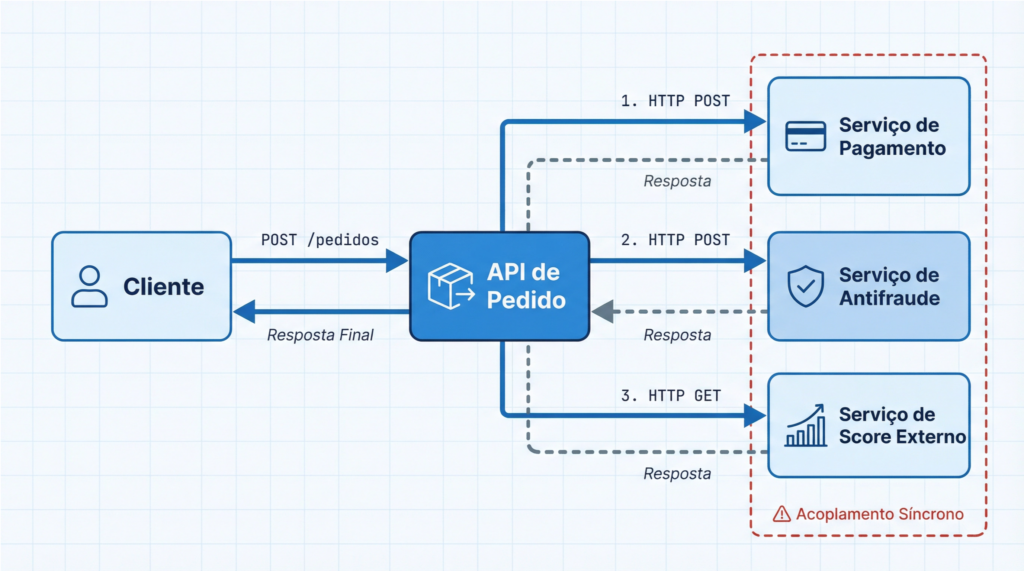
Nesse cenário, o tempo de resposta ao usuário depende da soma de todas essas etapas. Se o serviço de antifraude responder em 200 ms a mais do que o normal, o impacto chega no checkout. Se o serviço externo de score oscilar, o pagamento pode atrasar ou falhar. E mesmo quando a falha está longe da borda do sistema, quem sente primeiro é o cliente.
Na prática, integrações síncronas em cadeia se aproximam do comportamento de uma transação distribuída. Você coordena etapas em múltiplos sistemas, mas sem garantia real de consistência de ponta a ponta. Por isso, precisa conviver com consistência eventual, isto é, momentos em que os dados ainda não estão alinhados entre os serviços, mas tendem a se ajustar depois.
Para conviver com esse modelo, surgem mecanismos de proteção: timeout, fallback, retry e circuit breaker. Todos ajudam a reduzir o impacto de falhas, mas todos também adicionam complexidade. Em outras palavras, o fluxo continua funcionando, mas passa a exigir mais código defensivo, mais observabilidade e mais cuidado operacional.
O ponto central é simples: esse modelo não falha apenas por implementação ruim. Ele falha porque cria dependências frágeis em um ambiente que, por natureza, já é instável.
A ilusão do controle no HTTP
Uma das razões pelas quais o HTTP síncrono é tão usado é a sensação de controle. O fluxo parece claro: um serviço chama o outro, recebe a resposta e decide o próximo passo. Isso realmente simplifica o raciocínio local e facilita o tratamento de erro no mesmo contexto da requisição.
Só que esse controle é parcial.
Você controla quando chama. Você controla como trata a resposta. Mas não controla a latência da rede, a carga do outro serviço, uma queda momentânea no ambiente ou uma falha logo após o envio da resposta. Em sistemas distribuídos, isso importa muito.
Imagine uma operação de pagamento. O serviço A envia a requisição, o serviço B processa corretamente, mas a resposta se perde por instabilidade de rede. Para A, a operação parece falha. Para B, ela foi concluída. A partir daí surge um cenário ambíguo: repetir a chamada pode ser necessário, mas também pode gerar efeito duplicado se a operação não for idempotente.
É por isso que fluxos síncronos costumam parecer mais simples do que realmente são. O caminho feliz é direto. O problema está nas bordas, nas ambiguidades e nos estados intermediários.
Mensageria como estratégia de desacoplamento
Arquiteturas baseadas em mensageria partem de uma premissa diferente. O produtor não precisa que o consumidor esteja disponível naquele exato momento. Ele só precisa garantir que a intenção de negócio foi registrada e enviada para processamento.
Ao colocar um broker como Kafka, RabbitMQ ou Azure Service Bus entre os serviços, a responsabilidade de entrega, retenção, reprocessamento e absorção de picos deixa de estar no fluxo direto entre A e B e passa para a infraestrutura.
O desenho muda:
Serviço A
→ publica evento no broker
→ Serviço B consome quando estiver disponível
Essa mudança parece pequena, mas o efeito é grande. Em vez de propagar imediatamente uma indisponibilidade, o sistema ganha capacidade de absorver falhas transitórias. Se o consumidor estiver temporariamente fora do ar, a mensagem continua disponível para processamento posterior. Se houver pico de volume, a fila funciona como um amortecedor.
Isso não elimina problemas. Mas muda a natureza deles. Em vez de travar o fluxo no momento da requisição, o sistema passa a lidar com atraso controlado, reprocessamento e consistência eventual.
O custo real da mensageria
Mensageria melhora resiliência, mas não vem de graça.
Ela introduz novas preocupações operacionais. É preciso administrar brokers, monitorar filas, tratar mensagens paradas, lidar com DLQs (Dead Letter Queues), investigar fluxos assíncronos e garantir que consumidores possam reprocessar mensagens sem efeito colateral indevido.
Na prática, o custo aparece em quatro frentes:
Vantagens
- Reduz acoplamento temporal entre serviços
- Melhora a tolerância a falhas parciais
- Permite escalar produtores e consumidores de forma independente
- Absorve melhor picos de carga e variações de volume
Desvantagens
- Exige mais operação e monitoramento
- Torna o debug menos linear
- Introduz atraso entre causa e efeito
- Torna idempotência e observabilidade requisitos desde o início
A decisão, portanto, não deve ser ideológica. A pergunta certa não é “mensageria é melhor que HTTP?”. A pergunta certa é: o risco que estou reduzindo justifica a complexidade que estou adicionando?
Quando HTTP síncrono é a escolha certa
Apesar de todas as limitações, HTTP continua sendo a melhor opção em muitos casos.
Ele faz sentido quando a resposta precisa voltar imediatamente para o usuário de maneira síncrona, quando a operação depende do contexto exato da requisição e quando a dependência chamada tem bom nível de estabilidade e previsibilidade.
Casos comuns:
- autenticação e autorização
- consultas simples, como read models
- validações imediatas no fluxo da requisição
- orquestrações leves dentro de um mesmo bounded context
- APIs públicas com semântica clara de request/response
Se um usuário precisa saber na hora se o login foi aceito, se um formulário está válido ou se um dado pode ser exibido, o modelo síncrono é natural. Nesses cenários, colocar mensageria no meio tende a complicar o que já estava resolvido.
Quando mensageria deixa de ser opcional
Há situações em que insistir no síncrono começa a custar caro demais.
Isso acontece quando a operação não precisa de resposta imediata, quando o sistema precisa sobreviver a falhas parciais sem travar o restante do fluxo ou quando o volume de processamento pode variar de forma imprevisível.
Exemplos típicos:
- processamento de pagamentos
- atualização de estoque após uma compra
- emissão de notificações
- integrações entre domínios diferentes
- processos longos, como sagas
- eventos de domínio que disparam múltiplos consumidores
Pense em uma compra concluída com sucesso. O cliente não precisa esperar, na mesma requisição, que estoque, faturamento, antifraude, notificação e análise interna terminem tudo ao mesmo tempo. Tentar forçar isso no fluxo síncrono só aumenta latência, multiplica pontos de falha e deixa o sistema mais frágil.
Nesses cenários, a mensageria deixa de ser uma otimização e passa a ser uma forma de preservar o sistema sob carga e sob falha.
O erro mais comum: usar os dois sem critério
Um erro recorrente em arquiteturas híbridas é misturar os dois modelos sem uma regra clara.
De um lado, há sistemas que colocam fila em tudo, inclusive em fluxos que exigem resposta imediata. Do outro, há sistemas que insistem em HTTP para operações que claramente deveriam ser desacopladas. Nos dois casos, o resultado costuma ser ruim.
O critério mais útil não é começar pela tecnologia. É começar pelo significado do fluxo:
- Esse processo precisa de confirmação imediata?
- A falha dessa etapa deve bloquear o restante?
- O domínio tolera atraso?
- O resultado precisa ser consistente na hora, ou pode convergir depois?
Essas perguntas ajudam mais do que qualquer preferência por ferramenta. Porque a escolha entre síncrono e assíncrono não é, no fundo, uma escolha de protocolo. É uma escolha de comportamento do sistema.
Conclusão
HTTP síncrono continua sendo uma solução simples, útil e correta em muitos cenários. O problema não está no modelo em si, mas em tentar usá-lo em fluxos que exigem tolerância a falhas, absorção de carga e menor acoplamento entre serviços.
Mensageria, por sua vez, não resolve tudo. Ela troca simplicidade inicial por maior resiliência estrutural. Exige mais operação, mais disciplina e mais cuidado com idempotência, observabilidade e rastreabilidade. Ainda assim, em muitos contextos, esse custo compensa.
Na prática, bons times não tratam HTTP e mensageria como rivais. Eles entendem que cada modelo resolve um tipo diferente de problema. E o que separa uma arquitetura estável de uma arquitetura frágil, muitas vezes, é justamente saber onde cada um deve ser usado.