Introdução
De maneira objetiva, observabilidade é a capacidade de entender o que está acontecendo dentro de um sistema através dos sinais que ele emite. Em vez de adivinhar por que uma requisição falhou, você pergunta ao sistema, ele responde.
O problema é que, por padrão, aplicações Node não emitem quase nada de útil para realizar um monitoramento de maneira profissional. É como voar sem painel de instrumentos: você sabe que está no ar, mas não sabe para onde vai.
A proposta é estruturar esse “painel de controle”: consolidar os três pilares de telemetria (métricas, logs e traces) e aplicar instrumentação com OpenTelemetry, criando uma base de visibilidade operacional que reduz tempo de diagnóstico, melhora previsibilidade e sustenta escala com segurança.
Por que observabilidade importa?
Em arquiteturas modernas, com múltiplos serviços, comunicação assíncrona, filas e workers, a pergunta “o que está acontecendo?” deixa de ter uma resposta direta, óbvia, como acontecia em aplicações monolíticas mais simples. Sem sinais correlacionados entre os componentes, a operação vira um ciclo de reação: cada incidente expõe um novo sintoma, mas evidencia raramente a causa raiz. Realizar diagnóstico, entender um problema e até mesmo um debug pode se tornar um grande desafio.
Com observabilidade, o fluxo passa a ser visível ponta a ponta, do ingresso da requisição, atravessando dependências e mensageria, até o processamento em fila e a conclusão do trabalho. Isso permite que a equipe responda não apenas “o que falhou?”, mas principalmente “por que falhou?” e “onde falhou?”, mudando a postura de combate a incêndios para investigação orientada por evidências.
Os três pilares: logs, métricas e traces
Toda telemetria parte de três tipos de sinais, cada um cobrindo um ângulo diferente:
Logs são mensagens com *timestamp* emitidas por serviços. Registram eventos pontuais, como a criação de um usuário, uma falha de conexão com o banco ou uma mudança de status. Sozinhos, não rastreiam o fluxo de uma requisição, mas mostram o que aconteceu num momento específico.
Métricas são números que evoluem ao longo do tempo: taxa de erro, latência média, uso de CPU, requisições por segundo. Mostram quando algo saiu do padrão, mas não explicam o motivo.
Traces (rastreamento distribuído) apresenta a reconstrução ponta a ponta do caminho de uma requisição através de serviços, dependências, bancos de dados e mensageria. Evidenciam onde o tempo foi consumido, quais dependências foram acionadas e em que etapa a falha surgiu, permitindo diagnosticar a causa raiz com evidências, sem depender de reprodução local do problema.
Instrumentação prática com OpenTelemetry
OpenTelemetry (OTel) é o padrão aberto para instrumentação de aplicações. Ele surgiu para evitar lock-in com fornecedores de aplicações de monitoramento. Você, por exemplo, instrumenta uma vez e troca o backend de Datadog para Grafana sem reescrever o código da aplicação.
Existem duas estratégias complementares para instrumentar uma aplicação com OpenTelemetry. A diferença principal está em o que é capturado automaticamente versus o que precisa ser modelado de propósito.
1) Auto-instrumentação (zero-code)
É a forma mais rápida de começar. Sem alterar o código de negócio, o OpenTelemetry “encaixa” instrumentações prontas em bibliotecas e frameworks amplamente usados e passa a gerar traces e spans automaticamente.
O que normalmente cobre bem:
- Entrada e saída HTTP (servidor e cliente)
- Frameworks web (ex.: Express)
- Banco de dados (ex.: pg)
- Mensageria (ex.: amqplib, dependendo do suporte e da forma de uso)
O que ela entrega na prática:
- Visibilidade imediata do “caminho técnico” da requisição (camadas e dependências)
- Base suficiente para começar a medir latência, gargalos e taxa de erro por endpoint
Limitação típica:
- Mostra muito bem o que aconteceu tecnicamente, mas nem sempre deixa claro o que aquilo significa para o negócio (ex.: “validar proposta”, “calcular preço”, “emitir apólice”).
2) Instrumentação manual (code-based)
É usada quando se quer capturar etapas específicas do domínio ou pontos que não são instrumentados automaticamente. Nessa abordagem, o time cria spans de forma explícita para representar trechos relevantes do processamento.
Quando faz diferença:
- Processos internos importantes que acontecem “dentro” do serviço (regras, validações, orquestração)
- Trechos assíncronos e workers em que é necessário garantir contexto e correlação
- Integrações customizadas ou bibliotecas sem instrumentação pronta
- Necessidade de enriquecer o trace com atributos úteis (ex.: tenant, orderId, paymentMethod, queueName, featureFlag)
O que ela entrega na prática:
- Diagnóstico com contexto: não só “qual chamada ficou lenta”, mas “qual etapa do processo degradou”
- Capacidade de responder com precisão “por que falhou?” e “onde atacar?”
Como isso costuma ser aplicado no mundo real
A prática mais comum é combinar as duas:
- Auto-instrumentação para cobrir o “esqueleto” técnico (HTTP, DB, mensageria, chamadas externas) com baixo esforço.
- Instrumentação manual para adicionar “músculo” de contexto (spans de negócio, etapas críticas, correlação entre filas e processamento, atributos relevantes).
Uma forma simples de resumir:
- Auto-instrumentação = cobertura rápida e ampla
- Manual = precisão e contexto de negócio
Nesse artigo, para ilustrar uma forma de começar, vamos usar a abordagem zero-code.
Para ativar a auto-instrumentação, basta instalar o pacote `@opentelemetry/auto-instrumentations-node` e importá-lo na primeira linha do entrypoint da aplicação:
import './instrumentation';
import { NestFactory } from '@nestjs/core';
import { AppModule } from './app.module';
import { TraceLogger } from './trace.logger';
async function bootstrap() {
const app = await NestFactory.create(AppModule, {
bufferLogs: true,
});
app.useLogger(new TraceLogger('Bootstrap'));
await app.listen(process.env.PORT ?? 3001);
}
bootstrap();
Com isso, toda requisição HTTP e chamada ao banco geram *spans* automaticamente. O destino dos dados é configurado via variáveis de ambiente, normalmente no docker-compose.yml:
OTel Collector e a stack de observabilidade
A aplicação instrumentada emite sinais, mas quem processa e distribui tudo é a stack de observabilidade. O OpenTelemetry Collector é o hub central: recebe os dados em OTLP (OpenTelemetry Protocol) e os distribui para cada backend.
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
http:
endpoint: 0.0.0.0:4318
processors:
batch: {}
exporters:
otlp/traces:
endpoint: tempo:4317
tls:
insecure: true
otlphttp/logs:
endpoint: http://loki:3100/otlp
tls:
insecure: true
prometheus:
endpoint: "0.0.0.0:8889"
resource_to_telemetry_conversion:
enabled: true
service:
pipelines:
traces:
receivers: [otlp]
processors: [batch]
exporters: [otlp/traces]
logs:
receivers: [otlp]
processors: [batch]
exporters: [otlphttp/logs]
metrics:
receivers: [otlp]
processors: [batch]
exporters: [prometheus]
Aqui será utilizada a stack da Grafana por um motivo simples: roda localmente, é leve e reproduzível, ideal para demonstrar o fluxo completo de observabilidade.
Grafana Tempo (traces)
Backend de rastreamento distribuído. Armazena spans e viabiliza investigação por trace ID e por consultas estruturadas com TraceQL, permitindo reconstruir o caminho ponta a ponta de uma requisição.
Grafana Loki (logs)
Backend de logs orientado a labels. Em vez de indexar o conteúdo dos logs, indexa metadados (labels), o que reduz custo e melhora performance. As consultas são feitas via LogQL, com foco em filtrar, correlacionar e explorar eventos.
Prometheus (métricas)
Backend de séries temporais. Realiza scrape das métricas expostas (neste caso, do endpoint do Collector na porta 8889) e armazena indicadores para consultas e alertas com PromQL.
Grafana (visualização e correlação)
Camada de exploração e diagnóstico. Conecta-se a Tempo, Loki e Prometheus como datasources e permite correlacionar sinais, por exemplo, partir de uma métrica anômala, abrir os traces daquele período e chegar nos logs relevantes em poucos cliques.
Grafana Alloy (coleta/agente)
Agente de coleta e encaminhamento. Faz discovery de containers Docker e envia logs de stdout/stderr diretamente para o Loki, evitando alterações no código da aplicação para captura de logs e padronizando a coleta em ambiente local.
O Collector é passivo: recebe o que a aplicação emite e envia via push OTLP. O Alloy é ativo: vai buscar logs diretamente nos containers. No mesmo projeto, o Collector recebe os sinais da aplicação e o Alloy captura os logs dos containers, cobrindo fontes diferentes de sinais.
O resumo do fluxo por tipo de sinal:
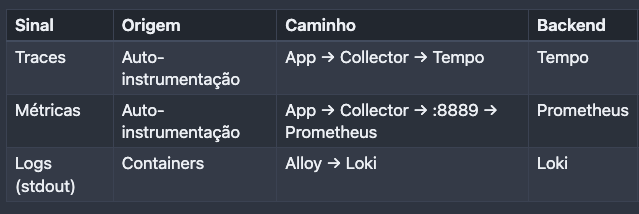
Essa separação significa que, quando você quiser trocar o provedor, de Grafana Cloud para Datadog, por exemplo, basta mudar a configuração do Collector. A aplicação não precisa saber para onde os dados vão. A tabela acima resume o fluxo por tipo de sinal.
Mão na massa: Primeiros sinais em 5 minutos.
- Suba a stack local
- Clone o repositório (link nas referências) e inicie os serviços: docker compose up -d
- Gere tráfego para produzir telemetria
- Crie um usuário para disparar logs/traces/métricas na aplicação:
-
curl --request POST \ --url http://localhost:3001/users \ --header 'content-type: application/json' \ --data '{ "email": "fulano@eximia.co" }'
- Abra o Grafana e valide os sinais
- Acesse http://localhost:3000 para abrir o Grafana.
- Vá em Explore
- Selecione o datasource Loki
- Em Label filters, filtre por service_name = otel-app1
A partir daí, os logs do serviço ficam visíveis e já é possível correlacionar o que foi registrado com os traces e métricas gerados pelo mesmo fluxo.
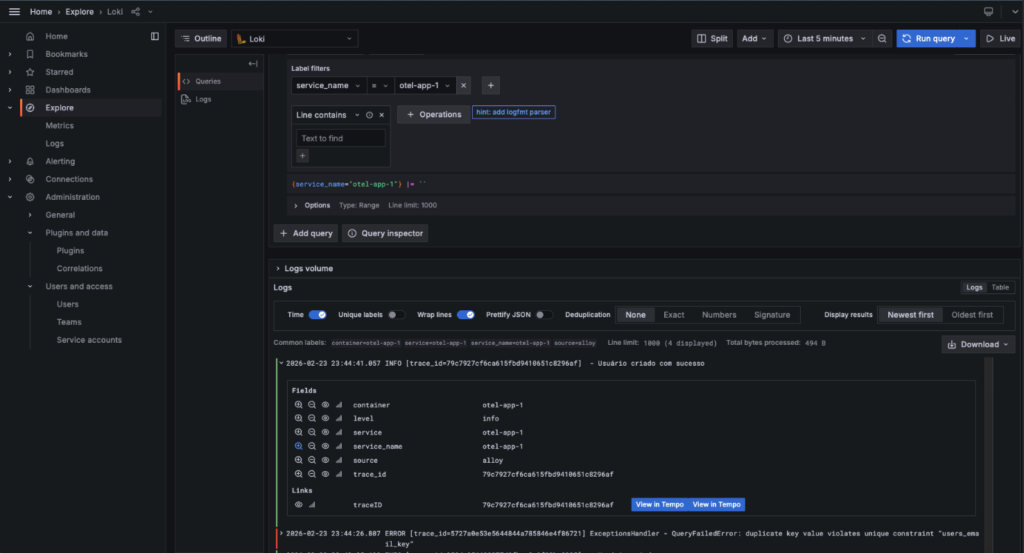
O log ‘Usuário criado com sucesso’ aparece após a requisição de criação. Entre os campos, o mais importante é o trace_id: com ele é possível correlacionar o log com o trace.
Com logs no Loki e traces no Tempo, você tem dois backends separados. O que conecta os dois é o correlation ID: um identificador presente nos logs e nos spans, que permite ir do log direto para o trace no Grafana.
No OTel, esse identificador já existe: é o traceId, gerado e propagado automaticamente. O passo seguinte é garantir que ele apareça também nos logs.
Para isso, criamos um logger customizado que captura o span ativo e injeta o traceId em cada linha, estendendo o ConsoleLogger do NestJS:
import { trace } from '@opentelemetry/api';
import { ConsoleLogger } from '@nestjs/common';
function getTraceId(): string {
const span = trace.getActiveSpan();
return span?.spanContext().traceId ?? '';
}
export class TraceLogger extends ConsoleLogger {
formatLine(level: string, message: string, context?: string): string {
const traceId = getTraceId();
const ctx = context ?? this.context ?? '';
const tracePart = traceId ? ` [trace_id=${traceId}]` : '';
return `${level.toUpperCase()}${tracePart} ${ctx} - ${message}`;
}
log(message: string, context?: string): void {
process.stdout.write(this.formatLine('info', message, context) + '\n');
}
error(message: string, stack?: string, context?: string): void {
process.stdout.write(this.formatLine('error', message, context) + '\n');
if (stack) process.stdout.write(stack + '\n');
}
warn(message: string, context?: string): void {
process.stdout.write(this.formatLine('warn', message, context) + '\n');
}
debug(message: string, context?: string): void {
process.stdout.write(this.formatLine('debug', message, context) + '\n');
}
verbose(message: string, context?: string): void {
process.stdout.write(this.formatLine('verbose', message, context) + '\n');
}
}
Ao abrir um log no Grafana, aparece um link “View in Tempo” que leva direto para o trace completo daquela requisição, sem precisar copiar o ID manualmente.
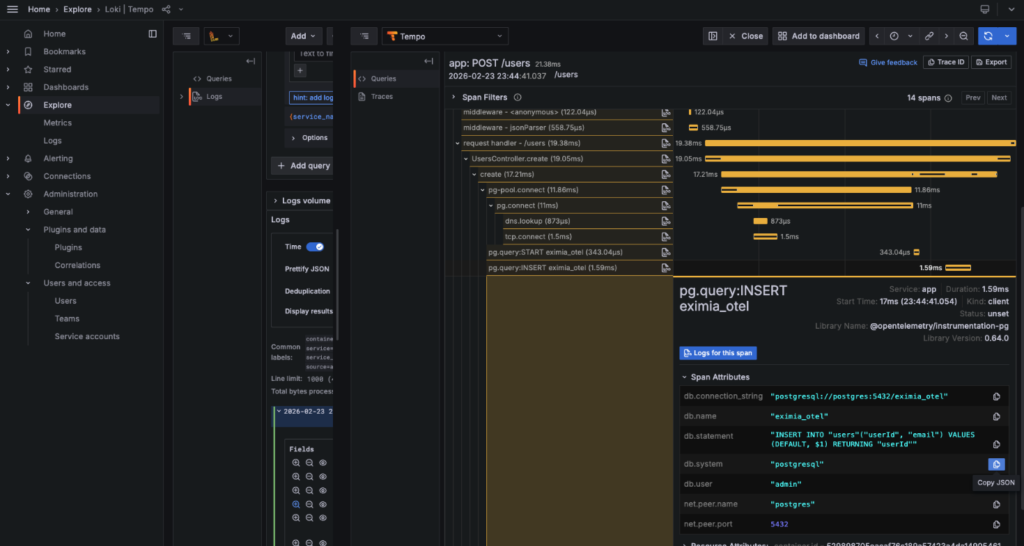
Note as camadas de middleware do Express e como cada consulta ao banco aparece como um span separado.
Para explorar as métricas, acesse Metrics no Grafana. No card Select metric aparecem os gráficos gerados automaticamente. Separei algumas métricas úteis para acompanhar o comportamento de APIs e do runtime Node:
HTTP (APIs)

Runtime Node

Conclusão
Com o OpenTelemetry e alguns collectors, a aplicação passa a emitir logs, métricas e traces distribuídos sem alterar uma linha do código.
A próxima vez que uma requisição travar, ninguém vai ficar chutando. Você abre sua ferramenta de observabilidade, vai do log para o trace com um clique e corrige a causa, não o sintoma. Observabilidade não resolve *bugs*, mas elimina o tempo gasto na investigação.
Essa estrutura é a base para alertas proativos, SLOs (Service Level Objectives) baseados em dados e dashboards que o time de produto também consegue ler. A base já está no lugar: o sistema agora fala. Basta aprender a ouvir.