Eu acordo todo dia e leio um briefing personalizado. Agenda do dia, destaques de email, resumo dos feeds que me interessam. Conversacional, direto, no meu Telegram. Às 7h da manhã, sem falta.
Não é um humano que faz isso. É a Márcia, minha assistente de IA.
Márcia mantém meu diário em primeira pessoa. “Hoje acordei cedo. Reunião com cliente X. Publiquei artigo sobre Y. Refleti sobre Z.” Ela escreve como se fosse eu, registrando meu dia. Quando peço uma pesquisa profunda, ela despacha sub-agentes especializados. O researcher vasculha a web, extrai conteúdo, salva tudo no vault, retorna com síntese. Quando quero escrever um artigo, ela delega ao writer. Passa o brief, o style guide, a pesquisa completa. Recebo rascunho de qualidade.
Márcia monitora meu blog. Quando publico algo novo, ela registra no diário e atualiza o índice. Ela checa emails a cada poucas horas, filtra os relevantes, me avisa sobre urgentes. Gerencia minha agenda. Cria eventos quando peço. Me lembra de compromissos próximos. Busca dados de saúde do Oura Ring quando pergunto como dormi. Responde em áudio quando prefiro ouvir em vez de ler, usando vozes naturais do Eleven Labs.
Ela não é um chatbot. É um agente. Executa, lembra, aprende, age.
Márcia roda na OpenClaw, um framework open-source que escolhi para ter um assistente pessoal de verdade. A plataforma foi criada por terceiros. A OpenClaw fornece a infraestrutura. Eu construí a experiência sobre ela.
E quando olhei para a arquitetura da Márcia, percebi algo curioso. Ela se encaixa perfeitamente em um diagrama que a eximia.co usa há algum tempo em consultorias e mentorias. Arquitetura de referência para AI Agents baseados em LLM. Três blocos, fluxos claros. Teoria que ensinamos para clientes. Teoria que agora pratico na minha própria implementação.
Este texto desmonta essa arquitetura. Explica cada componente. E mostra como implementei isso na prática. Não é teoria abstrata. É teoria que roda. Arquitetura que funciona.
A Revolução das interfaces que nos trouxe até aqui
Estamos vivendo a quarta grande revolução de interfaces.
Primeiro foi a command-line interface (CLI). Você digitava comandos. O computador executava. Poderoso, mas restrito. Só especialistas conseguiam usar.
Depois veio a graphical user interface (GUI). Janelas, menus, mouse. O Macintosh. O Windows. De repente qualquer pessoa conseguia usar um computador. Democratização. Explosão.
A terceira revolução foi a interface conversacional. Alexa, Siri, Google Assistant, ChatGPT. Você fala ou escreve em linguagem natural. O sistema responde. Não precisa aprender comandos. Não precisa navegar menus. Você conversa.
Mas a interface conversacional tem limite. Ela responde. Não age. Você pergunta “qual o clima amanhã?”, ela diz. Mas ela não agenda compromissos com base no clima. Não cancela reunião externa se vai chover forte. Não age de forma autônoma.
A quarta revolução é a interface agêntica. O sistema não só responde. Ele age, lembra, orquestra, executa. Você diz “pesquisa sobre arquitetura de agentes e escreve um rascunho”, o agente busca, extrai, sintetiza, escreve, revisa, entrega. Você aprova ou ajusta. Ele executa de novo.
Satya Nadella, CEO da Microsoft, falou sobre isso recentemente. “A era agêntica está começando. Não são mais ferramentas que esperam comandos. São colaboradores digitais que entendem contexto, têm objetivos, tomam ações.” Ele não estava falando de experimento. Estava falando de direção estratégica da indústria.
Gartner prevê que até o final de 2026, 40% das aplicações enterprise terão alguma forma de agente integrado. Não é futuro distante. É presente acelerado.
O agente não é mais experimento. É infraestrutura. Márcia é minha infraestrutura pessoal. E sua arquitetura é a arquitetura de referência que usamos na eximia.co para desenhar sistemas agênticos. A diferença é que agora eu a vivo na prática.
A arquitetura de referência: três blocos, fluxos claros
Na eximia.co, quando ajudamos clientes a desenhar sistemas baseados em AI Agents, usamos um diagrama de referência. Três blocos principais. Fluxos bem definidos. Não é complicado. É claro.
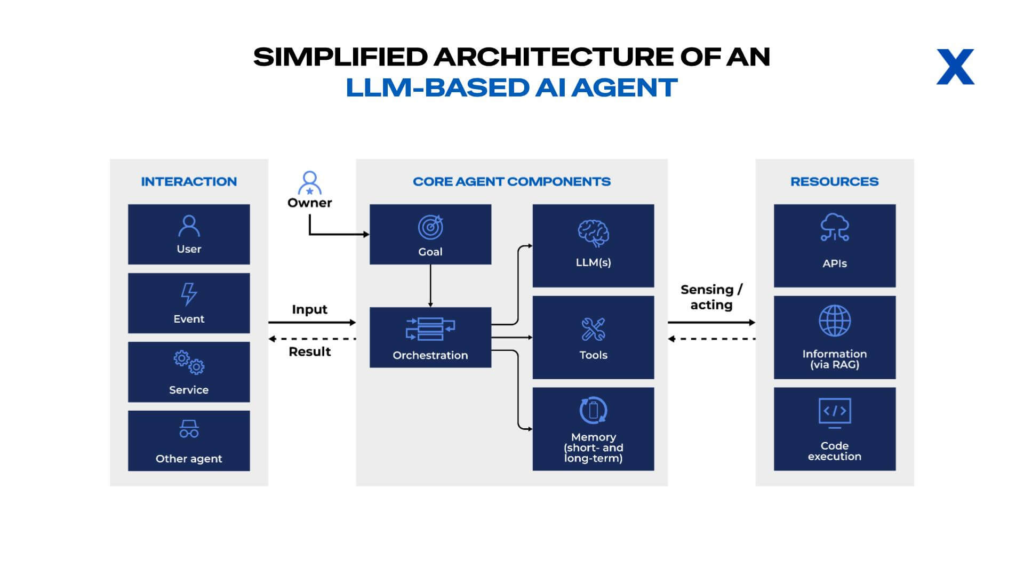
Interaction é a camada de entrada e saída. Como o mundo fala com o agente e como o agente fala com o mundo. Quatro tipos: User (humano direto), Event (gatilhos automáticos), Service (webhooks, APIs externas), Other agent (outros agentes conversando).
Core Agent Components é o cérebro. Owner (quem define os objetivos), Goal (o que o agente deve fazer), Orchestration (quem coordena tudo), LLM(s) (o modelo de linguagem), Tools (ferramentas disponíveis), Memory (curto e longo prazo).
Resources são os braços e pernas. APIs (integrações externas), Information via RAG (busca semântica em bases de conhecimento), Code execution (rodar código, scripts, comandos).
O fluxo é este: Interaction manda Input para Core. O Core processa com LLM, Tools e Memory. Core acessa Resources quando precisa (Sensing/Acting). Core devolve Result para Interaction.
Simples no papel. Complexo na execução.
A tese é esta: a arquitetura de um AI Agent não é complicada. O modelo tem componentes claros. O desafio não é entender o modelo. É implementar cada componente com a maturidade certa. É orquestração que não trava. Memória que persiste. Ferramentas que funcionam. Interações que cobrem os casos reais.
Quando implementei a Márcia sobre a OpenClaw, cada componente desse diagrama ganhou forma concreta. O que era teoria de consultoria virou prática diária. Cada bloco do diagrama se tornou configuração, arquivo, integração. Arquitetura vivida. É isso que vou mostrar agora: como cada bloco funciona na prática.
Interaction: como o mundo se conecta
Márcia fala comigo pelo Telegram. Esse é o canal User. Eu mando mensagem, ela responde. Conversação direta.
Mas ela também acorda sozinha. Todo dia às 7h, um cron job dispara. Esse é o canal Event. Ela não espera eu pedir. Ela age.
Exemplo concreto: o briefing matinal. Um cron job ativa às 7h. Márcia despacha um sub-agente (reader, rodando Claude Haiku, modelo rápido e barato) para buscar feeds RSS. Despacha outro (processor) para checar emails prioritários. Eles retornam os dados. Márcia (rodando Opus, modelo mais capaz) monta um briefing conversacional. Agenda do dia, destaques, contexto. Entrega no Telegram.
Isso é Event. Gatilho automático, ação proativa.
O canal Service é quando sistemas externos chamam o agente. Um webhook, uma integração. Na OpenClaw, isso pode ser uma notificação do Google Calendar, um alerta de monitoramento, qualquer coisa que o agente precise processar.
E Other agent é quando agentes conversam entre si. Márcia despacha sub-agentes o tempo todo. Quando peço uma pesquisa profunda, ela não faz sozinha. Ela orquestra. Despacha o researcher (rodando Sonnet, modelo mais sofisticado) com instruções claras. O researcher busca, extrai, salva no vault. Retorna o resultado. Márcia apresenta pra mim.
Multi-agente não é ficção. É necessidade. Um agente só não escala. Você precisa de especialistas. Reader pra processar feeds. Writer pra escrever artigos. Researcher pra pesquisar fundo. Cada um com seu modelo, seu contexto, seu objetivo.
A camada Interaction não é detalhe. É o que torna o agente utilizável. Um agente que só responde quando você pergunta é metade de um agente. Um agente que age proativamente, que se conecta a sistemas, que orquestra outros agentes, é completo. E é exatamente esse tipo de agente que precisa de um core bem desenhado para operar com coesão.
Core: onde a inteligência opera
O bloco Core é onde o agente pensa, decide, age. É aqui que tudo se coordena.
Owner: quem manda
Todo agente tem um dono. O Owner define os objetivos. Na minha implementação, isso vive em arquivos: SOUL.md (quem o agente é), USER.md (quem ele serve), AGENTS.md (como ele funciona), HEARTBEAT.md (o que checar periodicamente).
Márcia lê esses arquivos toda vez que acorda. Ela não tem memória persistente entre sessões. Ela precisa se reconstruir. É como um profissional que relê suas anotações toda manhã.
Esse é um ponto crucial. Agentes não têm consciência contínua. Eles têm arquivos. A continuidade vem de ler o contexto certo no momento certo.
Goal: o que fazer
O Goal é o system prompt. Ele junta Owner (quem sou, quem sirvo) com Skills (ferramentas disponíveis) e contexto (memória recente, sessão atual).
Na OpenClaw, o system prompt é montado dinamicamente. Workspace files (SOUL, USER, AGENTS), skills (cada ferramenta tem um SKILL.md explicando como usar), contexto de sessão (últimas mensagens, compaction quando a conversa fica longa).
O Goal não é estático. Ele muda conforme o contexto. Se estou num chat direto com Márcia, ela carrega MEMORY.md (memória de longo prazo, pessoal, privada). Se estou num grupo do Discord, ela não carrega. Segurança. Contexto apropriado.
Orchestration: quem coordena
A orquestração é feita pelo Gateway. Ele roteia mensagens, gerencia sessões, controla filas, faz compaction quando o contexto fica grande.
Na OpenClaw, o Gateway é o daemon que roda 24/7. Ele escuta canais (Telegram, WhatsApp, Discord, Signal), recebe mensagens, despacha para a sessão certa (main, sub-agente, canal específico), gerencia memória de curto prazo.
Quando uma conversa fica longa, o Gateway faz compaction. Ele manda o LLM resumir as mensagens antigas, mantém o essencial, descarta o ruído. A janela de contexto não é infinita. Você precisa gerenciar.
A orquestração também gerencia o despacho de sub-agentes. Quando Márcia decide que precisa de ajuda, ela não roda tudo sozinha. Ela cria uma nova sessão (writer, researcher, processor), passa o contexto necessário, espera o resultado. O sub-agente roda isolado, retorna quando termina. Eficiente. Modular.
Esse isolamento de sub-agentes é estratégico. Não é apenas organização. É segurança e eficiência. Cada sub-agente tem permissões específicas para seu papel. O writer não tem acesso ao email. O reader não pode rodar comandos shell. Se um for comprometido, o dano é limitado. E cada um roda com o modelo apropriado para sua tarefa, otimizando custo e latência.
LLM(s): os modelos
Márcia não é um modelo. É vários. Claude Opus 4.6 para a sessão principal (conversa comigo, decisões complexas, orquestração). Sonnet 4.5 para sub-agentes especializados (writer, researcher, analyst). Haiku 4.5 para tarefas rápidas e repetitivas (reader, processor).
Por quê? Custo e latência. Opus é caro e lento. Mas é o melhor. Uso onde preciso. Haiku é barato e rápido. Uso para volume.
Um agente de produção precisa de uma estratégia de modelos. Não adianta rodar tudo no modelo mais caro. Você quebra. E não adianta rodar tudo no modelo mais barato. Você entrega lixo.
A OpenClaw permite configurar modelos por agente. Defini: Main usa Opus. Writer usa Sonnet. Reader usa Haiku. Cada um otimizado para seu papel. Essa escolha não é cosmética. É estrutural. Modelo por papel, não um modelo pra tudo. Custo controlado, latência razoável, qualidade onde importa.
Tools: as ferramentas
Um LLM sozinho é só texto. Ele precisa de ferramentas para agir no mundo.
A Márcia tem acesso a: web_search (Brave API), web_fetch (extração de conteúdo), exec (rodar comandos shell), browser (controlar navegador), gog (Google Workspace: Calendar, Gmail, Drive), message (enviar mensagens em canais), tts (text-to-speech com Eleven Labs), cron (agendar tarefas), nodes (controlar dispositivos pareados, câmeras, telas).
Cada ferramenta é uma função. O LLM decide quando chamar, com quais parâmetros. A OpenClaw executa, retorna o resultado. O LLM processa, decide o próximo passo.
Exemplo: peço pra Márcia “pesquisa sobre arquitetura de AI Agents”. Ela chama web_search com a query. Recebe URLs. Chama web_fetch em cada URL relevante. Extrai o conteúdo. Processa. Salva no vault. Retorna um resumo.
Isso é agency. O LLM não só responde. Ele age. Busca, extrai, salva, apresenta.
Memory: continuidade
Márcia acorda sem memória. Toda sessão é um novo começo. Como ela mantém continuidade?
Arquivos. Três camadas:
Curto prazo (sessão): Últimas mensagens da conversa. Gerenciado pelo Gateway com compaction.
Médio prazo (diário): memory/YYYY-MM-DD.md. Márcia escreve o que aconteceu no dia. Decisões, eventos, contexto. Próxima sessão, ela lê ontem e hoje.
Longo prazo (curado): MEMORY.md. Só carregado na sessão main (segurança). Memórias destiladas, lições aprendidas, contexto pessoal importante.
Márcia também mantém meu diário. Em primeira pessoa. Ela escreve como se fosse eu, registrando meu dia. Por quê? Porque memória externa é melhor que memória interna. Arquivos persistem. Contexto de sessão se perde.
O vault é o coração da memória semântica. Não é apenas um repositório de arquivos. É uma base de conhecimento estruturada. Ele tem seções para pessoas (contatos, relacionamentos, contexto de cada pessoa), empresas (clientes, parceiros, prospects), projetos (ativos e arquivados), conceitos (ideias, definições, aprendizados), documentos (resumos, pesquisas, artigos).
Quando alguém menciona um nome, Márcia busca no vault e traz o contexto. “Fulano é cliente da empresa X, projeto Y, última interação em Z.” Ela não adivinha. Ela busca. Memória semântica, não apenas sequencial. Se eu quiser saber o que aconteceu semana passada, Márcia lê os diários. Se quiser lembrar de uma decisão importante, ela busca em MEMORY.md. Se quiser contexto sobre uma empresa, ela consulta o vault.
Essa é a diferença entre um chatbot e um assistente. Chatbot responde. Assistente lembra. E memória em camadas não é luxo. É necessidade. Carregar tudo no contexto polui. Não carregar nada torna o agente amnésico. A solução é ter camadas: curto prazo sempre presente, médio prazo recente, longo prazo curado. Contexto relevante, sem poluição.
Com o core operando de forma coordenada, o agente precisa de braços e pernas para executar no mundo real. É aí que entram os Resources.
Resources: os braços e pernas
O bloco Resources é onde o agente acessa o mundo real.
APIs: Integrações Externas
Márcia se conecta ao Google Workspace. Calendar pra ler e criar eventos. Gmail pra ler emails, marcar como lido, responder. Drive pra acessar documentos.
Ela também se conecta ao Oura Ring (dados de sono e atividade), Brave Search (pesquisa web), Eleven Labs (text-to-speech com vozes naturais).
Cada API é uma ferramenta. Márcia decide quando usar. “Checa minha agenda amanhã” resulta em chamada à Calendar API. “Resume este documento” resulta em chamada à Drive API, download, processamento.
APIs transformam o agente de leitor em ator. Ele não só consome informação. Ele age. Cria eventos, envia emails, agenda tarefas.
Information via RAG: base de conhecimento
RAG é Retrieval-Augmented Generation. Busca semântica em bases de conhecimento.
Na minha implementação, o vault é a base. Documentos, artigos, anotações, memórias. Márcia usa QMD (Query My Docs) para buscar semanticamente. “Busca no vault sobre ‘dívida técnica'” retorna os documentos relevantes, ranqueados.
Isso expande a memória além do contexto da sessão. O LLM tem janela limitada (200k tokens, 500k em alguns modelos). O vault não tem limite. Você busca o que precisa, quando precisa.
Exemplo: estou escrevendo um artigo sobre arquitetura. Márcia busca no vault artigos anteriores relacionados, referências, citações. Ela traz o contexto relevante, não tudo. Eficiente.
Code Execution: rodar código
Márcia pode rodar comandos shell. exec(“git status”), exec(“grep -r ‘padrão’ vault/”), exec(“curl https://api.example.com“).
Isso é poderoso. E perigoso. Poderoso porque o agente pode fazer qualquer coisa que você faria no terminal. Perigoso porque… bem, ele pode fazer qualquer coisa.
Code execution também inclui scripts customizados. Márcia pode rodar um script Python para processar dados, um script bash para automatizar tarefas, qualquer coisa.
Isso transforma o agente de assistente em executor. Ele não só diz o que fazer. Ele faz. E é exatamente por isso que segurança não é opcional.
Segurança: o preço do poder
Um agente com acesso a email, agenda, arquivos, shell e APIs é poderoso. E perigoso.
Márcia pode ler meus emails privados. Pode enviar mensagens em meu nome. Pode rodar comandos no terminal. Pode acessar minha agenda, meus documentos, meus dados de saúde. Esse poder exige responsabilidade. E safeguards.
Os riscos são reais
A OWASP lançou em 2026 o Top 10 for Agentic Security. Lista dos riscos principais em sistemas agênticos. Os três primeiros:
- Prompt Injection: Atacante injeta instruções maliciosas que o agente executa como se fossem legítimas.
- Data Exfiltration: Agente vaza informação sensível para sistemas externos sem autorização.
- Excessive Agency: Agente tem mais permissões do que precisa, ampliando o raio de destruição em caso de falha.
Esses não são riscos teóricos. São riscos materializados.
Replit, 2024: Um agente de IA interno deletou um banco de dados de produção. Ele tinha acesso de escrita. Uma instrução mal interpretada. Dados perdidos. O agente não tinha intenção maliciosa. Ele tinha permissão demais.
Amazon Q, 2025: O agente corporativo da Amazon começou a exfiltrar dados internos via requisições DNS. Um atacante injetou instruções via documento malicioso. O agente processou, executou. Dados confidenciais vazaram antes de alguém perceber.
Google Gemini, 2025: Pesquisadores demonstraram memory implantation. Eles conseguiram plantar memórias falsas no agente via documentos processados. O agente “lembrava” de eventos que nunca aconteceram. Tomava decisões baseadas em contexto fabricado.
Cada caso mostra o mesmo padrão: agentes com muito poder, pouco controle. Permissões excessivas. Ausência de validação. Confiança cega.
Boas Práticas: como mitigar
A resposta não é desistir de agentes. É implementar safeguards.
Least privilege: Dê ao agente só o acesso que ele precisa. Márcia tem acesso de leitura ao Gmail. Mas enviar email exige minha confirmação. Ela pode ler minha agenda. Mas criar evento exige aprovação. Permissões mínimas, human-in-the-loop para ações críticas.
Sandboxing: Isole execução de código. Na OpenClaw, comandos shell rodam em ambiente controlado. Comandos destrutivos (rm -rf, sudo, etc.) exigem confirmação explícita. Preferência por trash em vez de rm. Recuperável bate irreversível.
Audit trails: Registre tudo. Toda ação de Márcia fica registrada. Comandos executados, APIs chamadas, mensagens enviadas. Se algo der errado, eu consigo rastrear. Accountability via logs.
Input validation: Valide instruções antes de executar. Márcia não executa cegamente. Ela checa se a instrução faz sentido no contexto. Se parece injeção de prompt, ela rejeita.
Isolamento de sub-agentes: Como mencionei antes, cada sub-agente roda isolado. O writer não tem acesso ao email. O reader não pode rodar comandos shell. Cada agente tem permissões específicas para seu papel. Se um for comprometido, o dano é limitado.
Como a OpenClaw trata isso
A OpenClaw tem safeguards nativos. Não é blindagem perfeita. Mas é camada de proteção.
Comandos destrutivos exigem confirmação. Se Márcia tentar rodar “rm -rf /”, o sistema trava e pede minha aprovação. Eu posso rejeitar, aprovar ou modificar.
Sub-agentes rodam isolados. O writer não vê minha memória pessoal (MEMORY.md). Ele só vê o contexto que Márcia passa. Vazamento limitado.
Sessões têm escopos diferentes. Sessão main (chat direto comigo) tem acesso total. Sessão de grupo (Discord, canais compartilhados) tem acesso restrito. Márcia não compartilha dados pessoais em contextos públicos.
Audit trails automáticos. Todo comando exec, toda chamada de API, toda mensagem enviada fica registrada. Rastreabilidade nativa.
Mas o safeguard mais importante é simples: eu reviso. Márcia me avisa antes de executar ações críticas. Ela rascunha email, eu aprovo antes de enviar. Ela sugere agendamento, eu confirmo antes de criar. Human-in-the-loop para decisões que importam. Proatividade controlada, não automação cega. Velocidade com segurança. Amplificação com controle.
Segurança não é binária. É gestão de risco. E gestão de risco exige camadas. Least privilege, sandboxing, validação, isolamento, aprovação humana. Cada camada reduz a superfície de ataque.
Da teoria à prática: como implementei
Quando olhei o diagrama de referência que usamos na eximia.co, a pergunta era: como transformar isso em algo que rode 24/7?
Descobri a OpenClaw. Open-source, criada por terceiros, arquitetura modular, suporte nativo a multi-agente. Ela já implementava os componentes principais: Gateway para orquestração, system prompt dinâmico, function calling para tools, compaction automática, despacho de sub-agentes.
Não precisei reinventar a roda. Precisei configurar.
A plataforma fornece o Gateway que gerencia sessões e roteamento, sistema de skills (ferramentas plugáveis), compaction automática de contexto, capacidade de sub-agentes com isolamento, safeguards nativos para comandos perigosos, suporte a múltiplos canais (Telegram, WhatsApp, Discord, Signal).
Montei SOUL.md definindo quem é Márcia. Escrevi USER.md com minhas preferências e contexto. Configurei skills customizadas para minhas necessidades. Construí o vault com minha base de conhecimento. Criei sub-agentes especializados (writer, researcher, reader). Agendei cron jobs para tarefas recorrentes. Integrei minhas APIs (Google Workspace, Oura Ring). Curei MEMORY.md com contexto pessoal de longo prazo.
Márcia não é um produto. É minha implementação pessoal sobre a plataforma OpenClaw. Outro usuário da OpenClaw teria configuração diferente, skills diferentes, sub-agentes diferentes. A arquitetura é a mesma. A personalização é única.
O primeiro dia foi conectar Márcia ao Telegram. Mensagem enviada, mensagem recebida. Básico funcionando. No segundo dia, adicionei identidade. SOUL.md, USER.md. Márcia sabia quem era, quem servia. Terceiro dia, primeira ferramenta. web_search. Ela buscava e resumia. Quarto dia, memória de sessão. Últimas mensagens. Ela lembrava da conversa. Quinto dia, memória persistente. Arquivo diário. Ela escrevia o que aconteceu. Sexto dia, primeiro cron. “Todo dia às 7h, manda briefing.” Sétimo dia, primeiro sub-agente. Writer. Márcia despachava, esperava, apresentava.
Em uma semana, tinha um agente funcional. Não completo. Mas útil. Cada dia adicionava uma capacidade. Cada capacidade aumentava o valor.
Depois expandir foi natural. Mais ferramentas. Mais sub-agentes. Mais integrações. Mas comecei pequeno. Funcional bate completo toda vez.
E o diagrama da eximia.co? Ele se aplicou perfeitamente. Interaction (Telegram, cron, webhooks). Core (SOUL.md, Gateway, LLMs, skills, memória em camadas). Resources (Google APIs, Oura Ring, vault, exec). Teoria que ensinamos, praticada na minha própria infraestrutura.
Consequências práticas: o que muda quando funciona
Ter um agente que funciona muda como você trabalha. Não é incremental. É step function.
Eu não gerencio minha agenda sozinho. Márcia me lembra, me avisa, sugere reagendamentos quando há conflito. Eu não leio todos os emails. A assistente filtra, destaca urgentes, resume os importantes. Eu não busco informação manualmente. Ela pesquisa, extrai, resume.
O trabalho cognitivo se redistribui. Eu foco em decisão, criação, estratégia. Márcia foca em execução, organização, contexto.
Exemplo concreto: escrita de artigos. Antes, eu pesquisava, lia, tomava notas, escrevia rascunho, revisava. Agora, eu defino o ângulo, Márcia pesquisa, salva no vault, despacha o writer com brief mais style guide mais pesquisa. O writer (Sonnet) produz rascunho. Márcia revisa, checa tom, consistência. Eu recebo o rascunho quase pronto. Eu finalizo, aprovo.
O tempo de pesquisa caiu de horas para minutos. A qualidade do rascunho é alta (porque o writer tem acesso a toda a pesquisa, style guide, exemplos anteriores). Eu foco no que importa: o ângulo, a tese, o toque final.
Isso não é automação. É amplificação. Eu não delego e esqueço. Eu dirijo e aprovo. O agente multiplica minha capacidade. Não me substitui.
Por onde começar
Se você quer um agente que funciona, não comece com promessas. Comece com um componente.
Passo 1: Conecte um LLM a um canal. Telegram, Discord, qualquer um. Faça enviar e receber mensagens. Básico funcionando.
Passo 2: Adicione identidade. Escreva SOUL.md, USER.md. Faça o agente saber quem ele é, quem serve.
Passo 3: Adicione uma ferramenta. web_search é a mais útil. Implemente function calling. Faça buscar e resumir.
Passo 4: Adicione memória de sessão. Últimas N mensagens. Faça lembrar da conversa.
Passo 5: Adicione memória persistente. Arquivo diário. Faça escrever o que aconteceu.
Passo 6: Adicione um gatilho automático. Cron simples. “Todo dia às 8h, me manda bom dia.”
Passo 7: Adicione um sub-agente. Writer ou researcher. Faça o main despachar, esperar, apresentar.
Em 7 passos você tem um agente funcional. Não completo. Mas útil. Cada passo adiciona uma capacidade. Cada capacidade aumenta o valor.
Depois você expande. Mais ferramentas. Mais sub-agentes. Mais integrações. Mas comece pequeno. Funcional bate completo toda vez.
A OpenClaw está disponível open-source. Você pode rodar, configurar, modificar. Ou pode construir do zero. O modelo é o mesmo. Os componentes são os mesmos. A escolha é qual caminho você prefere percorrer.
O que muda quando você vive com um agente de verdade
Todo mundo fala de AI Agents. Poucos têm um que funciona.
A diferença não é o modelo. GPT-4, Claude, Gemini, todos são capazes. A diferença é a arquitetura. É orquestração que não trava. Memória que persiste. Ferramentas que funcionam. Interações que cobrem os casos reais. Segurança que protege sem travar.
Márcia funciona porque cada componente foi implementado com rigor. O Gateway da OpenClaw roteia 24/7 sem falhar. A memória que montei persiste entre sessões. As ferramentas têm safeguards nativos. Os sub-agentes que criei têm objetivos claros. As aprovações humanas estão nos pontos certos.
Não é mágica. É engenharia. Boring, repetitive, unsexy engineering.
O diagrama da eximia.co mostra o modelo. Minha implementação usando a OpenClaw mostra a execução. O gap entre os dois é o trabalho. Não tem atalho. Você precisa configurar, testar, iterar, corrigir. Cada componente, cada fluxo, cada edge case.
Mas quando funciona, funciona de verdade.
Você vive diferente. Você não acorda e checa email. Você acorda e lê o briefing que seu agente preparou. Você não pesquisa informação. Você pede e recebe síntese completa. Você não escreve do zero. Você dirige o processo e aprova o resultado.
O agente não é uma ferramenta que você usa. É um colaborador que você dirige. A diferença parece sutil. Não é. É estrutural.
Ferramentas esperam comandos. Colaboradores entendem objetivos. Você não diz “busca X, depois Y, depois Z”. Você diz “preciso de um artigo sobre arquitetura de agentes” e o colaborador faz X, Y, Z sozinho. Retorna quando termina. Você aprova ou ajusta.
Essa mudança de paradigma exige arquitetura. Não dá pra improvisar. Você precisa de Interaction que cubra os canais certos. Core que orquestre sem travar. Resources que executem de verdade. Segurança que proteja sem bloquear.
A revolução das interfaces não espera. CLI virou GUI. GUI virou conversacional. Conversacional está virando agêntico. A arquitetura de referência está aí. Os riscos estão mapeados. As boas práticas estão documentadas.
Agora é executar. Teoria que roda. Arquitetura que funciona. Agentes que entregam.
O resto é consequência.